WebScrapping Project Part - 1


Today we will learn Webscrapping, how we can convert it into a Project. What are the benefits, and objective of this project.
Firstly, if u are working on any data project, then u get data from the client side.
Sometimes, u need to get the derived data. For that, there are various techniques, depends on sources which should be used.
Eg. if some data is there on certain site, so if u want to remove that, than what to do? how to remove that? how to automate?
Here comes into the game, 'WebScrapping'.
Bcoz u can acquire a lot of data through web scrapping. Above that, ML, DL, Computer Vision, NLP Model can be implemented.
Eg. There is Flipcart website. We search iphone11 and find the list of product. And clicking on one of the products, we see the reviews given for it.
Now, if so many people have given reviews, we won't be able to read ten thousand's of reviews. So, we will build such an algorithm, eg. sentimentalizer, which will get all reviews summary and give it in form of report to you.
Before that, you need to go to website and get the reviews.
As a human being, u will have to get reviews one-by-one. But we dont want to do that.
So, our objective for today's project is that all the reviews here for a particular product we will scrap and store somewhere.
So let's start.
We will also see how we can automate using python. Also, we will be deploying on AWS and Azure.
First, we import some libraries in jupyter notebook.
from flask import Flask, render_template, request,jsonify
from flask_cors import CORS,cross_origin
import requests
from bs4 import BeautifulSoup as bs
from urllib.request import urlopen as uReq
import logging
logging.basicConfig(filename="scrapper.log" , level=logging.INFO)
app = Flask(__name__)
First, we import requests.
Then, we import from bs4, beautifulSoup, for beautifying entire data, as bs.
Then,from urllib library , urlib.request, import urlopen as uReq.
Then, we import logging which is old.
Now, we go to flipcart main website, 'flipcart.com', we see homepage and then we put the product name in the search bar to search the product.
So, 1st step is we got to main website of flipcart page.
When we search something on flipcart, it puts the search value in querystring and sends it to server (git request).
Now, what you will do is go to products one by one and get all the reviews. And analyze them.
1st we searched "iphone11" now we get save the base url as :
flipkart_url = "https://www.flipkart.com/search?q=" + "iphone12"
Then, we get the link in output on printing flipkart_url.
We parameterize "iphone12" by a variable.
flipkart_url = "https://www.flipkart.com/search?q=" + searchString
We need to click on url in output.
But we don't want to click on url to go to flipcart.
urllib library provides function urlopen to automatically open the url.
So, we take the alias name 'uReq' given to 'urlopen' and pass the variable in it, and assign it to a variable:
uClient = uReq(flipkart_url)
On printing uClient, u get HTTPResponse.
So, u need to get information from the client.
so u write :
flipkartPage = uClient.read()
Here, u are reading the whole page.
Data in the 'flipkartPage' is same as : Right Click + View Page source on the flipcart page.
Now we need to beautify the data, so we use bs.
flipkart_html = bs(flipkartPage, "html.parser")
We pass dump ("flipkartPage" variable) to bs, and bcoz it is HTML page, we use html parser and we align/beautify the page. And assign it to flipkart_html variable.
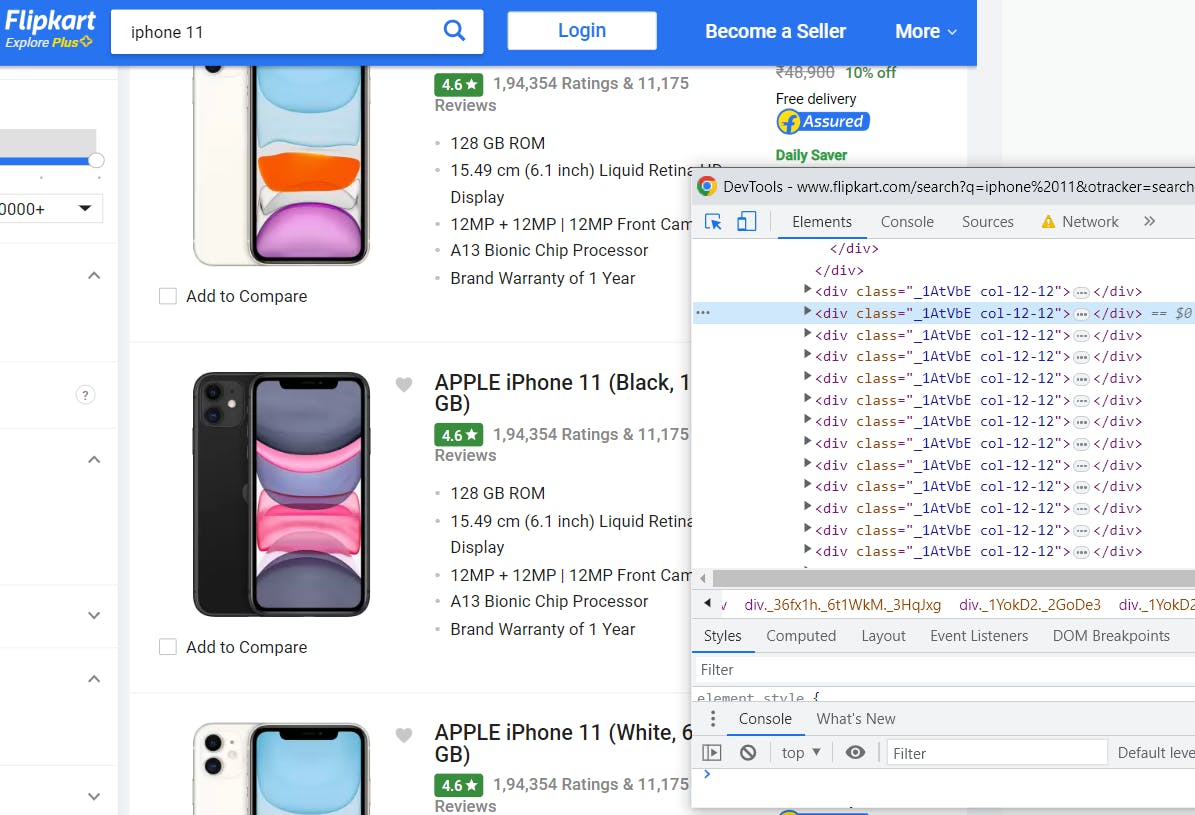
Now, we got the page data, but we need to click on page to get the reviews. So how to do that?
Go to page -> Press F12
Click on "Select an element" button on top-left corner.
Now we hover over the mouse over product list boxes, and we see different div tags for different products.
Now, inside div tags, we find href tags.
Href tags are the url's thru which u can click the product. We already learnt how we open the url. By clicking url in automatic way, one-by-one, then we can go inside and get the data.
Our goal is to get this url. Temporarily, we get this URL and append it to "flipcart.com". So, we get link to directly go to the product after appending:
"https://www.flipkart.com" + "/apple-iphone-14-pro-gold-128-gb/p/itme5895e593585d?pid=MOBGHWFHXPC3NFFY&lid=LSTMOBGHWFHXPC3NFFYC5Y9VU&marketplace=FLIPKART&q=iphone+14+pro&store=tyy%2F4io&srno=s_1_3&otracker=AS_QueryStore_OrganicAutoSuggest_2_9_na_na_na&otracker1=AS_QueryStore_OrganicAutoSuggest_2_9_na_na_na&fm=Search&iid=262ec10c-8e62-41a9-9b84-7d11ebcabbdd.MOBGHWFHXPC3NFFY.SEARCH&ppt=sp&ppn=sp&ssid=gu3utbvvpc0000001682667259310&qH=73a41d19c3188cc2"
Now, we are sure that we need to get this url to go to the product. And we need URL for all products' list.
Now, all this things are available inside "div" tag and "class", as we have got a key+value pair:
We can find any tag using "find()".
So, we find div, and inside it we find class:
flipkart_html.find("div", {"class": "_1AtVbE col-12-12"})
We find for all tags and assign it to bigbox variable:
bigbox = flipkart_html.findAll("div", {"class": "_1AtVbE col-12-12"})
On printing one of the element from bigbox list:
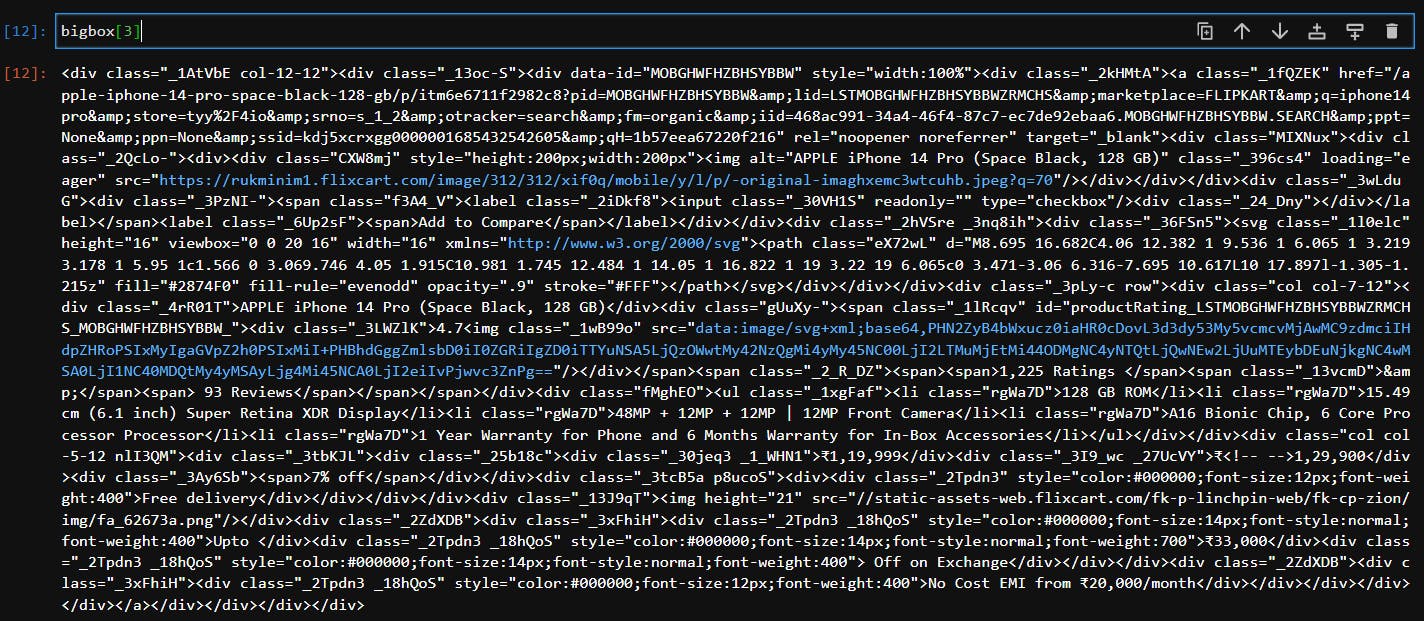
Now we want to reach href, so there is div in div in div then there is 'a' tag.
So we write: bigbox[3].div.div.div.a['href']
Note: 1st 3 div tags of no use so we delete them:
del bigbox[0:3]
"https://www.flipkart.com" + bigbox[3].div.div.div.a['href']
Now we have hyperlink in href. We have to get numerous such links, so we do in a for loop:
for i in bigbox: print("https://www.flipkart.com" + i.div.div.div.a['href'])
We have got product links. Now, we store that in a variable.
productlink = "https://www.flipkart.com" + bigbox[3].div.div.div.a['href']
Start Getting data from Product link:
product_req = requests.get(productlink)
Now we will go to the link page, and get data one-by-one.
We again use beautifulSoup and add text of product request:
product__html = bs(product_req.text,'html.parser')
So, bs will get the text, beautify it according to html, and it will be saved in product__html.
We find div & class for comment box and save it:
comment_box = product__html.find_all("div",{"class":"_16PBlm"})
len(comment_box)
To find commenters' names:
for i in comment_box: print(i.div.div.find_all('p',{"class":"_2sc7ZR _2V5EHH"})[0].text)
To find Rating:
for i in comment_box: print(i.div.div.div.div.text)
Another Method:
rating_box = product__html.find_all("div",{"class":"_3LWZlK _1BLPMq"}) ##another method using loop
for i in rating_box: print(i.text)
For comment headers:
for i in comment_box: print(i.div.div.div.p.text)
For actual comments:
comment_box[0].div.div.find_all('div',{'class':''})[0].div.text